
Image Edited from AMD.
On June 15, AMD announced it had acquired MEXT, a small software company with an unusual pitch: make cheap NAND flash look like DRAM to the operating system, so a server can run with far less of the expensive stuff. Terms weren’t disclosed, and AMD picked up MEXT’s engineering team along with the technology.
For a company that sells CPUs and GPUs, buying a memory-software startup might look like a side quest. It isn’t. Memory has quietly become the most painful line item in an AI server, and AMD just bought a way to stretch it.
Memory, not compute, is the bottleneck
The expensive part of a modern AI box is increasingly the RAM around the accelerators, not only the accelerators themselves. Two things are happening at once.
First, DRAM got expensive in a hurry. Conventional DRAM contract prices jumped roughly 93–98% quarter over quarter in Q1 2026, pushing industry revenue up about 81% in a single quarter. The cause is structural: memory makers are pouring wafer capacity into high-bandwidth memory (HBM) for AI accelerators, and HBM is greedy. A single HBM4 wafer displaces roughly three conventional DRAM wafers, so every gain in HBM output comes at the expense of the ordinary DDR5 that everything else needs. We tracked where those prices are heading, and the early signs of buyers pushing back, in a recent look at the mid-2026 DRAM and NAND market.
Second, a lot of the DRAM already installed sits idle. MEXT cites cloud-provider studies showing memory utilization often drops to 50% or below, meaning more than half the data in RAM is “cold,” allocated and paid for but rarely touched. By MEXT’s own accounting, DRAM now makes up 60–90% of the cost of an individual server, against a global DRAM spend north of $100 billion a year. Expensive, scarce, and half-wasted is a bad combination, and it’s exactly the gap MEXT goes after.
What MEXT actually does
The core idea is memory tiering, and it’s older than MEXT. Operating systems have swapped pages to disk for decades. The catch with classic swapping is that when an application reaches for a page that got pushed to storage, it stalls while the system fetches it. On a latency-sensitive workload, that stall is the whole ballgame.
MEXT’s answer is prediction. Its Predictive Memory Engine watches how an application touches memory and uses a model to guess which pages currently sitting in flash will be needed next. It moves those pages back up into real DRAM before the application asks for them. Cold pages get demoted to flash; pages about to turn hot get promoted in advance. If the prediction is good often enough, the application sees DRAM speeds while the machine physically holds far less DRAM.
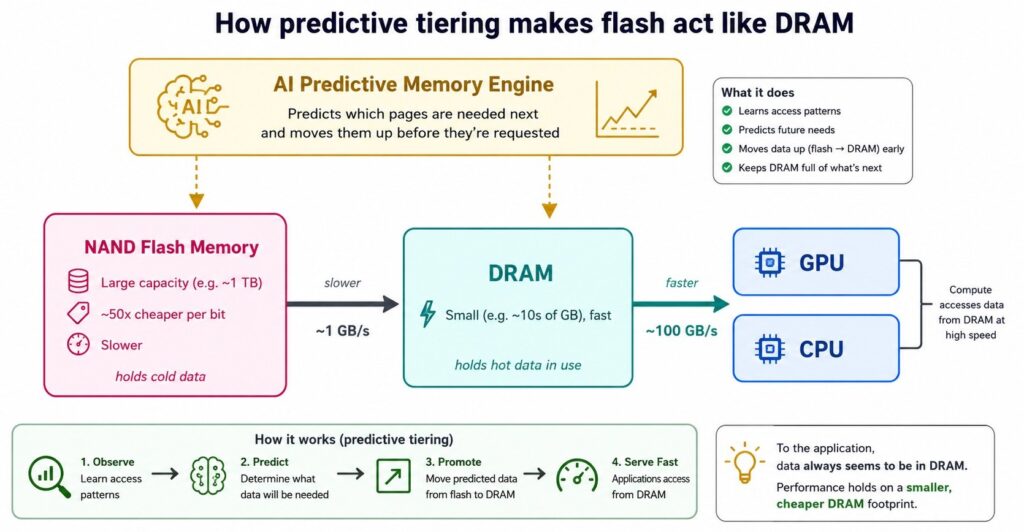
How Predictive Tiering Makes Flash Act Like DRAM
It’s worth noting who built this. MEXT’s chief scientist is Carl Waldspurger, whose name will be familiar to anyone who worked with VMware’s memory management. Predicting and reclaiming underused memory is more or less his life’s work. AMD isn’t buying a science project so much as a mature take on a hard problem, plus the people who understand it.
The practical claims, from MEXT, are modest enough to be believable: roughly 2–4x more usable memory on existing hardware, or about half the DRAM cost for the same performance, installed as software in a few minutes with no application changes. Those are vendor numbers and real workloads will vary, but they’re a different order of claim than “replace your RAM.”
How much flash tiering really saves
Flash genuinely is far cheaper than DRAM per bit. MEXT describes it as a “50X lower-cost tier,” and independent analyst Citrini Research put rough figures on the gap across the three memory types in an AI server:
| Memory tier | Estimated cost per GB | Role in an AI server |
|---|---|---|
| HBM3E / HBM4 | ~$15 | Fastest tier, bonded to the accelerator; holds model weights and the decode path |
| DDR5 (standard DRAM) | ~$2.75 | Conventional system memory and the hot working set |
| QLC NAND flash | ~$0.05 | Cheap, high-capacity overflow tier for cold data such as idle KV-cache pages |
Per-GB figures are Citrini Research estimates from mid-2026 and move with the market; treat them as one analyst’s snapshot, not a fixed price. The per-bit gap also narrows as you compare faster, more write-durable flash.
Here’s the part that gets lost in the excitement. A 50x gap in media cost is not a 50x cut to your memory bill. You still need a DRAM hot tier, flash is slower and wears out under heavy writes, and only the genuinely cold data can move down without a performance hit. The realistic payoff is the one MEXT actually advertises (somewhere around half the DRAM cost, or a few times the capacity), not a 98% saving. The big ratio explains why the idea is worth pursuing. It doesn’t land in your budget intact.
Why does cold data tolerate slow flash at all? Because not all memory access is equally urgent. In AI inference, the single largest memory consumer is often the KV cache, the running record of everything a model has generated so far in a conversation. It’s read in long sequential runs and grows with context length. Sequential reads are exactly what flash handles well, and they’re forgiving of latency in a way that a model’s weight-decode path is not. That asymmetry is the opening tiering exploits.
Apple had the same idea on your phone
If this sounds familiar, Apple published the consumer-device version back in 2023. Its paper, LLM in a Flash (later published at ACL 2024), tackled the problem of running a language model bigger than a phone’s DRAM by keeping the model’s weights in flash and streaming them into memory on demand. With techniques the authors call windowing and row-column bundling, both tuned to how flash likes to be read, they ran models up to twice the size of available DRAM and reported inference speedups of 4–5x on CPU and 20–25x on GPU versus naively loading from flash.
Different setting, same insight. Whether it’s a data-center rack or an iPhone, the move is to stop treating DRAM as the only place real work can happen and start using flash as a slower, much larger extension of it, with software smart enough to hide the seams.
Where this leaves the rest of us
AMD buying MEXT is one more sign that the memory hierarchy is being rebuilt around scarcity. Expensive HBM and DRAM hold the hot working set; cheap NAND catches the overflow; software shuttles data between them. That doesn’t shrink demand for DRAM — the hot tier still has to be fast and there’s never enough of it — but it does change the math on what’s worth keeping, buying, and reselling.
For anyone managing hardware through that shift, the secondary market is doing something interesting. When new DDR5 is scarce and priced like it’s 2026, the server memory and enterprise SSDs sitting in decommissioned gear are worth a real second look before they get wiped and scrapped. Modules that were an afterthought two years ago can carry meaningful resale value in a tight market, and which generation you’re holding (DDR4 versus DDR5) matters more than it used to. If you’re retiring servers, it’s worth knowing what the parts are actually worth now rather than assuming they’re junk.
The tiering trend won’t make memory cheap. It’s a sign of how expensive memory has become — expensive enough that turning flash into part-time DRAM is now a feature worth acquiring a company for.